
Introduction
In my Master Degree's Thesis I worked with neural networks that predict depth from a single image.
In particular, in this work, I studied unsupervised neural networks that are trained without the use of the ground truth depth data normally associated with the LIDAR scan or the disparity map obtained from cameras.
The evaluation of these networks is done using another sensor that provides such precise data that we take it as ground truth. Usually, the existing evaluation technique, present in the literature, is based on the comparison between the value of the lidar scan, taken at the instant closest to the image, projected within the limits of the image, and the depth value associated with the pixel of the neural network prediction1. Some problems can arise. In fact, in the most used datasets the single laser scan is rather sparse and often the position of the LIDAR sensor on the platform does not allow to scan parts of the scene. Using this approach you can only obtain a partial evaluation of your data, as considerable parts of the scene are not evaluable. The image below shows this approach.
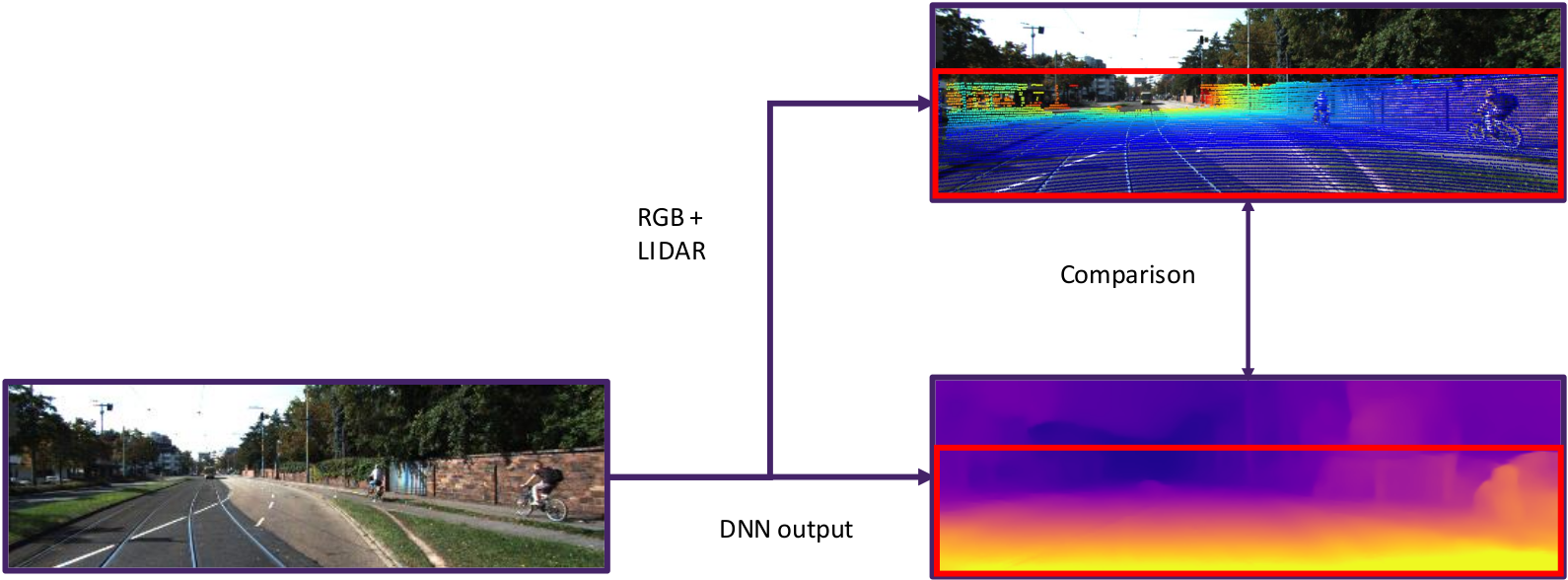
Work description
To overcome this limitation, this work presents a new performance evaluation methodology that is based on the alignment of multiple LIDAR scans to obtain a denser ground truth with more points at different intervals of distance. Trying to apply this solution I found some problems:
- How to align pointclouds;
- How to handle occluded pixels (or group of pixels). In fact, using multiple scans at different moments in time, parts of the scene are sampled that are not actually visible with respect to the camera point of view;
- How to manage the presence of dynamic obstacles in the scene. This problem was not been addressed in the context of this work.
The proposed pipeline consists of three phases. The first is the alignment of scans, the second the projection of the points in the image, and the last one is the filtering of the occlusions.
Scan Alignment
The proposed approach uses a succession of scans taken in an interval of time following the acquisition of the image. The first technique used is based on alignment using only the information given by a sensor such as GPS or visual odometry. Given how GPS in an urban environment is not accurate enough, the pointcloud that is generated in this way shows visible inconsistencies, such as the misalignment of walls, as shown in the figure. Consequently, to reduce this error, the solution adopted consist of: roughly align the pointclouds using the position data (gps or visual odometry) and then were applied pointcloud registration algorithms, capable of obtaining the rigid transformation between the two pointclouds considered. The result of this approach is a much more consistent pointcloud. This is an example of a pointcloud generated by several alignments.
 Projection of 3D points into the 2D image
Projection of 3D points into the 2D image
Having obtained a precisely aligned map, the next step is to project the three-dimensional points into the virtual 2D image plane corresponding to the camera's point of view. For each point, the depth value is saved and all points that do not fall within the limits of the image are discarded. If multiple points are projected into the same pixel, the point with the smallest depth value is saved.
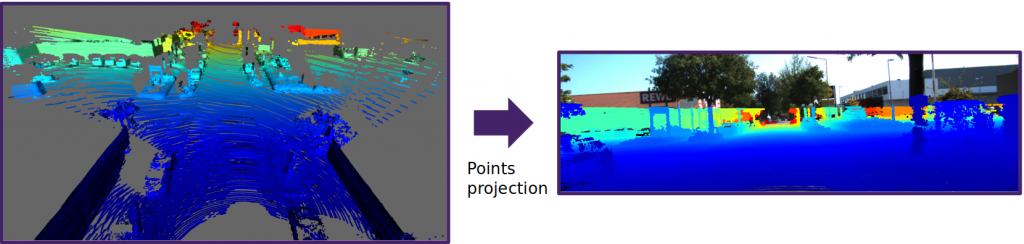
Occlusion filtering
By registering numerous pointclouds, the projection of the points on the image plane can produce a depth map with a high degree of noise due to the fact that the scans were acquired in different positions and at different time. So when the points are reprojected, some are occluded with respect to the image acquisition time. This problem is not the same problem typical of graphic computing. Since the LIDAR pointclouds are scattered and there is no surface information inside them, as the pointclouds represent only an unordered list of points, to solve the problem of occluded points, was applied an occlusions filter2 . This filter is able to perform a local surface interpolation between points around the point currently considered to define which points are or are not visible from the observer's point of view. For each point a cone is constructed on the projection line leading to the projection center. If there are points in the volume of the cone then that point is occluded otherwise it is visible. The image below shows the application of the occlusion filer.

Evaluation
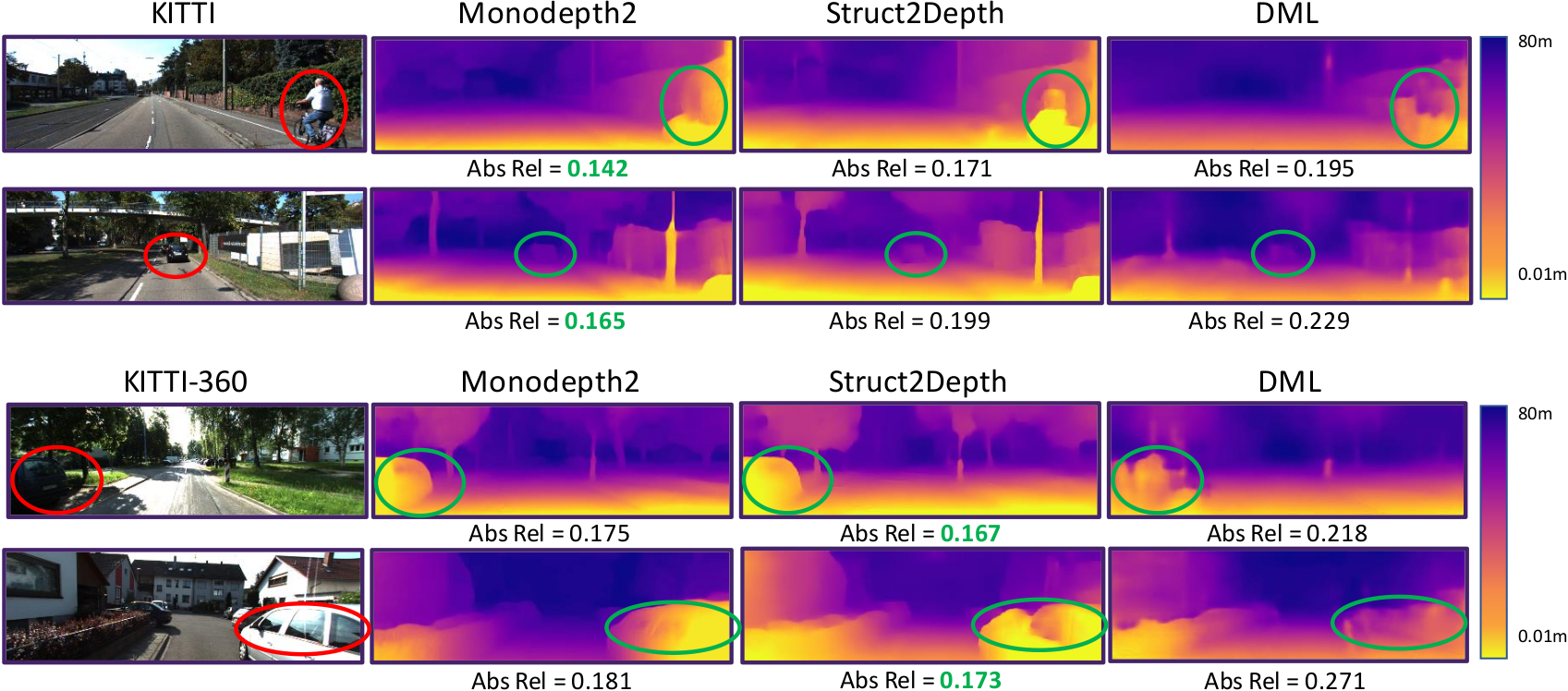
For the evaluation were chosen three neural networks3,4,5 that are part of the state of the art in the literature on unsupervised depth estimation. They were trained following the experiment set of the KITTI dataset6, which is commonly used in the literature for this task. The networks are then evaluated on the new KITTI-360 dataset7. Furthermore, a third dataset called Oxford Robotcar dataset8 was chosen. This dataset is not often used in the literature for depth estimation because it is very complex as there are many dynamic scenes in it.
The work contains a qualitative and quantitative analysis of the results from the application of the neural networks to the datasets.
Here are shown some of the qualitative analysis of the work with the score of the absolute relative error for each image.
The thesis and the full presentation can be downloaded here:
Thesis - Carlo_Radice_master_degree_thesis.pdf (331 downloads )
Presentation - Carlo_Radice_master_degree_thesis_presentation.pptx (320 downloads )
References
[1] David Eigen, Christian Puhrsch e Rob Fergus. ≪ Depth map prediction from
a single image using a multi-scale deep network ≫ . In: Advances in neural
information processing systems 27 (2014).
[2] Ruggero Pintus, Enrico Gobbetti e Marco Agus. ≪ Real-time rendering of mas-
sive unstructured raw point clouds using screen-space operators ≫ . In: Procee-
dings of the 12th International conference on Virtual Reality, Archaeology and
Cultural Heritage. 2011, pp. 105–112.
[3] Clément Godard et al. ≪ Digging into self-supervised monocular depth estima-
tion ≫ . In: Proceedings of the IEEE/CVF International Conference on Compu-
ter Vision. 2019, pp. 3828–3838.
[4] Vincent Casser et al. ≪ Depth prediction without the sensors: Leveraging struc-
ture for unsupervised learning from monocular videos ≫ . In: Proceedings of the
AAAI conference on artificial intelligence. Vol. 33. 01. 2019, pp. 8001–8008.
[5] Hanhan Li et al. ≪ Unsupervised monocular depth learning in dynamic scenes ≫ .
In: arXiv preprint arXiv:2010.16404 (2020).
[6] Andreas Geiger et al. ≪Vision meets robotics: The kitti dataset ≫ . In: The
International Journal of Robotics Research 32.11 (2013), pp. 1231–1237.
[7] Yiyi Liao, Jun Xie e Andreas Geiger. ≪ KITTI-360: A novel dataset and ben-
chmarks for urban scene understanding in 2d and 3d ≫ . In: arXiv preprint
arXiv:2109.13410 (2021).
[8] Will Maddern et al. ≪1 year, 1000 km: The Oxford RobotCar dataset ≫ . In:
The International Journal of Robotics Research 36.1 (2017), pp. 3–15.